基本的に外部 API 呼び出ししかないコードをいろいろ分解してだいたい TDD っぽく作ったよという話。今回はフレームワークに頼れる部分がなく、全体のパーツを自覚的に整理しながら作り上げていく必要があったので頭の整理をしておく。自分のやっていることはゼロかイチかではなく、概ねどこかしらにテストコードはあるけど網羅はしていなくて、だいたい今回のような感じで進めているような気がする。
だいたいの流れ
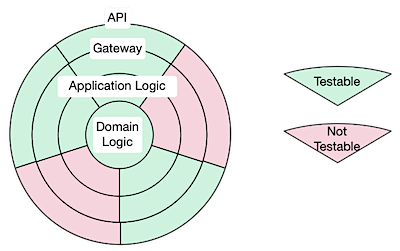
クリーンアーキテクチャっぽい円の外側から攻めていった。何しろ思ったように API が動くのか動かないのか分からないと作りようがないので、まずはそこから。1
- (非TDD)実際の API の動作確認
- (非TDD)API の response を再利用しやすいようにある程度パターン別に収集(テストコードを利用してアプリケーションの一部だけを動かす)
- (TDD)API アクセスのコードの一部を stub out しながら API Client 部分を実装
- できる範囲で API の動作を mock サーバや emulator で閉じ込めて「分離」
- (TDD)API に依存しつつアプリケーション全体の文脈を強く表すボキャブラリーとインターフェイスを用いた Facade 的なものを用意2
ここまでは stub / mock / emulator でどうにかなった。
気をつけていたのは Gateway 的な部分で、例えばストレージ系の API を呼ぶ必要のある API Client の部分は Repository パターンのような汎用的なインターフェイスを用意しつつ、もう一つ内側の Gateway の部分では Repository をあまり意識させず、単にやりたいことをメソッドとして持つようにしておいた3。
どうにかならない部分は処理の流れ的にほぼ後行程にしかないので文字通り後回しにした。これはそうなるようにアーキテクチャを選んでいたからできたことでもある。
そしてようやくアプリケーション全体の流れ。
- (非TDD) Application Logic (API の初期化と処理全体の流れ)の実装。最低限の初期化周り以外はほとんど自動テストしていない。
今回これで回せた理由は以下の二つだと思っている。
一つめは、そもそも今回はアプリケーションをサーバレスのピタゴラスイッチで実現することにしたこと。一つ一つのアプリケーションの役割は十分に小さいのでミスが入りにくい。
もう一つは、流れに関するロジックを図で言うところの Gateway か Domain に押し付けるようにしたから。
例えばアプリケーションロジックのように見えるものでも API 呼び出しの比率が高いものは Gateway の中に閉じ込めることで API 側で回せている TDD の中で完結させることができるならできるだけそうしたのだ。全体の流れとしては何らかのメソッドを呼んでいるだけにする。
逆に完全にプレーンなオブジェクトだけで表現可能なものは、
- (TDD)プレーンなオブジェクトに対して API に依存するオブジェクトからメソッドを通じて値オブジェクトを渡す形で独立させてロジックを実装
していった。
この部分が最初から見えていてプレーンなオブジェクトに抽出できていたらドメイン駆動っぽいのだけど、残念ながら自分の場合は API call 部分からどうやって testable にするか順番に引き剥がしていって、全体の流れのロジックを書く段階になって完全に逆サイドにロジックを押し付けるという戦術に結果的になった。
まとめ
アプリケーション全体を以下のように分解して考えることで、外部 API call だらけのアプリケーションでも開発の中盤はだいたい TDD できることが分かった。
- そもそものアプリケーションの流れを小さく分解
- API call 部だけの TDD
- API call とアプリケーション全体の流れの中間に入る部分の TDD(Gateway)
- 一切の API call と距離を置くプレーンなオブジェクトでロジックを記述する部分の TDD
今回は手元で再現できる emulator や mock サーバ、抽象化するライブラリのある API を自分で選ぶことができたが、そうでない場合はテスト環境を TDD のための装置として
- まずは deploy と環境構築の自動化
からやる必要があるだろう。それすらできない場合は…どうするのがいいんだろう。
むりくりDT blog: メディアヴィジョンって、こっそり**されていたのですね。
げへ。
Kacis シリーズが e-frontier の製品になってて、kacisbook.net には終了のお知らせ、mvi.co.jp は正引きできなくなってますな。
まぁ個人的にはプロノート/マイノートが発売される前後くらいから情報の整理は Wiki に移行していたので、あとは過去の資産をどう整理するかだけなのですが。
あー。サイト直さないといけないんだな。なんかオススメしてたような気がするし。つーか高くなってないすか、これ。
ネットワークの接続が変わった。
firewall がきつくなった。
traceroute できなくなった。
うーん。
ring の TENBIN では 九州ギガポッププロジェクトが近いそうだ。どこそれ。 を見ても ring サーバはどこだか分からないし。
を見ても ring サーバはどこだか分からないし。
へぇ。んーでもこれ man じゃーないんだな。
開発スピードと完成度と、ドキュメントの分かりにくさを考えると VikiWiki はステた方がいいのか?(^^;
AddModules の記述は必要
公式サイトのドキュメントでは
#AddModule mod_ruby.c
が書かれているが、実際にはコメントアウトしてるとソース垂れ流しになってしまう。
実行属性は必要
これは実に残念。でも Forbidden になるのでソース垂れ流しにはならない。
どこかのサイトで見つけたこの記述
AddHandler ruby-script .rbx .rbx
は要らなかった
ファイルの拡張子に応じて SetHanlder する記述が必要
<Files *.rbx>
SetHandler ruby-object
RubyHandler Apache::RubyRun.instance
</Files>
結果
VikiWiki は mod_ruby 化したら確かに速くなったが、permission の関係でエラーがあちこちで出るようになった。setup.rb に頼らず自力でそのままファイルを展開した方がマシだったろうか? 本家に mod_ruby でも動くと書いてあったからやったのだが、鵜呑みにしすぎか? 面倒くさくなってきたので今日はこの辺で。
mod_ruby の本当のおいしさはやっぱ embedded ruby、eRuby なんだよな。<% %> なのは ASP も睨んでのことですね。確かに ASP での利用も可能なようです。
優先度は高くなかったはずなのだが、VikiWiki のバージョンを上げた。理由は Farm 機能。Farm 機能の運用実績では Hiki が筆頭だが、Hiki はやはり書式が貧弱なので、PukiWiki 互換の書式を使うことができる VikiWiki で Farm を起こそうと考えた。
いつも思うことだが、バックアップや世代管理を個人の作業に期待するのは愚策である。基本的にはそんなにマメに世代バックアップを用意するなんてばからしくやってられない。しかしだからと言って共同の作業スペース(Windows や Mac のファイル共有をイメージすれば分かりやすい)上のデータをすべて世代管理するなんて、膨大すぎて非現実的である。
「いわゆるコード」の場合、CVS で管理していれば working copy と repository は自動的に分離される。したがって repository そのものが爆発することは、まぁ運用ポリシーにもよるがそんなにないだろう。しかし repository と working copy が同居しやすい場合((例えば Zope や WebDAV 経由の Subversion なんかがそういう状態になりやすいだろう。実際には working copy と repository はイコールにはならないが、手軽なので「確認用の環境を用意しない運用になりやすい」んじゃないかと思う。))、リポジトリの爆発という問題とどうつきあうのかという、けっこう深刻な問題が発生する。
あ、cvs admin みたいにこの revision は必要ないから削除とか、そういう操作ができればいいのか?(もちろんすべてのファイルについてそんなことやっちゃいられないが。) Subversion は次世代のバージョン管理として期待値はでかいが、クライアント環境をあまり選ばない(CVS みたいに面倒なことを気にしなくてよい)分、repository の管理能力を問われそうな感じだな。あ、Zope + Subversion てのも手かな? 普段 Zope にどかどか突っ込んでいって、ちゃんとしたバージョンの段階で Subversion に突っ込んで publish、ZODB のサイズを見て不定期に pack を行う。あ、これいいかもしんない。
- Zope + CVS
- Subversion + CVS
- Zope + Subversion
- Subversion + Zope
なんかの組み合わせがなくはないのかな? とりあえず操作性や柔軟さを考えて CVS をフロントには置かないってことで。