
Stimulus: A modest JavaScript framework for the HTML you already have.
Stimulusはテストしにくい
Stimulus は DOM の影響範囲を閉じ込めつつ、reactive system を強制せず、バックエンドとフロントエンドに無用な断絶を生まない、実に reasonable な選択肢として使い勝手がよいが、一方で生 DOM を使ったり DOM と Controller の bind がマジカルに解決されてしまい、ユニットテストを書きにくいという課題を抱えている。
StimulusのControllerを実際にテストする際に必要なもの
2021年9月現在、ライトな JavaScript のテスト環境としては Node.js を利用するのがよくあるパターンと思われる。しかし Stimulus は Virtual DOM を使わないので Node.js 上でテストするには以下の準備が必要になる。
- Mocha - the fun, simple, flexible JavaScript test framework
- jsdom/jsdom: A JavaScript implementation of various web standards, for use with Node.js
- rstacruz/jsdom-global: Enable DOM in Node.js
※ なお、今回はテスティングフレームワークとして Mocha を利用する。これは Jest を使うよりどんな準備が必要かを分かりやすくするためである。
今回用意したバージョンは以下の通り。
- Mocha 9.1.1
- JSDOM v17
- jsdom-global 3.0.2
生DOM部分のテストではjsdom-globalが便利だけど注意も必要
コードがシンプルになるのは以下のように実行して global に window, document オブジェクトを利用できるようにする方法になる。
mocha -r jsdom-global/register
こうすると
テストケースのコードの中ではどこでも document や window へアクセスすることができる。
逆に言うと、
let や var で初期化してはいけない
ことになる。せっかく inject しておいた document や window が壊れてしまう。
jsdom-globalを利用することについて
賛否はあるとは思うが、DOM に依存するコードを書く際に、完全に scope を閉じ込めようとするとかえって都合が悪いこともある。
これは JavaScript を書くすべての人に通用するノウハウではないかもしれないが、3rd party のコードを inject しながらその機能を利用したコードを書くことはよくある。このような場合、現実世界では DOM は global で巨大な singleton であり、いくつも生成できるものではないし、3rd party のコードがそもそもその global な singleton であることに依存していたり、うっかり複数回初期化すると動作が壊れる可能性もある。(例えば Google の global site tag によって定義される gtag() をうっかり複数回呼ぶと動作が意図と食い違う可能性がある。)
ということで、この本物の DOM の特徴に合わせておくと DOM にアクセスする function を新たに定義してテストコードから呼びたいという場合にも特別なことをする必要がなくなる。
ただし、当たり前だけどこういうコードは並列実行できない。Facebook が Virtual DOM を作り Jest を用意してるのはこういう理由なんだね。
具体的なテストコード
jsdom-globalを利用しつつテスト対象のDOMを組み立てる
Mocha で BDD-style で書いている場合は以下のように document の中身を書き換えてしまうとよい。
beforeEach(() => {
document.body.innerHTML = `
<div data-controller="some">
<button data-action="some#upCount">up !</button>
</div>
`
})
Stimulusのアプリケーションをテストする方法
必要な準備は以下の二つ
- MutationObserver を Node.js の文脈で global access できるように
- DOM 書き換えと controller の register からの bind の queue をちゃんと待つ
1 については以下のコードで実現できる。
before(() => {
global.MutationObserver = window.MutationObserver
})
これは Stimulus が DOM の MutationObserver に無条件に依存したコードになっているので、Node.js で動かす場合に global にぶら下げ直す必要があるからである。
2 については setTimeout(() => {}, 0) が必要ということ。具体的には以下のようなコードになる。
it('', () => {
const app = Application.start()
app.register('some', SomeController)
setTimeout(() => {
document.querySelector('button').click()
}, 0)
})
まとめ
今回は Stimulus を利用したコードのテスト方法として
- Mocha
- jsdom-global
を利用したシンプルな方法を紹介した。DOM が gloal な singleton であることを前提にした方法だが、一方で並列実行には向いていないので、JavaScript が本当に大規模になったらこの方法は合わないかもしれない。
もっとも並列実行に向いていないのは DOM を直接書き換えている部分だけなので、それ以外を並列実行するように設定するという方法でもよいかもしれない。(Controller の中で I/O などに直接タッチしてるとダメだけど、これはちゃんと DI してテストの時に差し替えるとか、作り方を注意すればいいだけ。)
※ 以下はもう古い情報です。Evernote 3.2 からはきちんと fav は local に cache されて勝手に消えたりしません。
Evernote をちょこちょこ試しているんだけど、iPod touch ユーザーとしていちばんつらいのはノートの情報は都度ネットワークから落としてくること。これ、注意してないとハマる。今見たばかりのノートはキャッシュされているんだけど、いくつか違うノートを見てから戻ってくるとまたネットワークからの再取得になる。このとき、iPod touch がネットワークに繋がっていなければノートを再び開くことはできない。
なーんーだーかーなー。
iPhone ならいいと思うんだ。でも現状の Evernote は iPod touch にはつらすぎる。クラウドは常にあるとは限らないのだ。
そこでノートやメモなどで検索したら以下のようなアプリが見つかった。
- Memos Lite
- 画像非対応
- スプリングノート :: ウィキ基盤の オンラインノート
- 独自サービス
- NoteMaster for iPhone and iPod Touch :: Kabuki Vision
- GoogleDocs連携
個人的には Evernote は単なるテキストメモではなく画像や PDF を添付できるところが気に入っている。主な目的は地図。iPod touch では常に Google Map を参照できるとは限らないためである。
ということで一つ目の Memos Lite は画像を貼れないのでボツ。
二つ目の SpringNote は Evernote のように独自にサービスを構築しているものなんだけど、結論から言うと Evernote と同じようなキャッシュの問題があって常用はしづらい。また操作感も Evernote より GoogleDocs に近く、手早くメモを残す感じでもない。なんだろう、よくできているんだろうけど、Evernote のような「うまい割り切り」を感じない。
三つ目の NoteMaster はアプリだけ用意してバックエンドは GoogleDocs と連携するというもの。よくよく探すとこの手のアプリは案外たくさん見つかる。なるほどな。これなら独自サービスの開発をしなくてもアプリの開発だけで済む。個人の開発やスモールスタートのビジネスとしては賢い方法だと思う。容量の問題も何もかも Google 任せ。
当然 GoogleDocs バックエンドなので GoogleDocs にできることは一通りできる。画像も貼れる。
しかし!
画像を拡大表示できない!
これじゃー使えないよ! 「なんとなく貼ってあるのが分かる」程度じゃー地図としてはまったく役に立たない。
ということで Evernote 代替アプリ探訪は一時棚上げ。なかなか iPhone 用に出回っている情報だけでは iPod touch はものすごく快適!にはならない。
え、画像を拡大して見れるだけなら Dropbox でいいじゃん? いやいや、Dropbox はファイルが生で見えているので、やはり情報としてはそんなに扱いやすくないの。地図とメモをワンセットのノートとして扱えて画像を拡大して見れるというところが Evernote の便利なところなわけだから。
『RESTful Webサービス』読んでんですよ。まぁあらかた読んだんです。いちばん気になっているのはリソースの設計の部分なんですが、これを URI にマップするときにどうにもうまくいかないものが出てきて、しかもまだ解消していないので、それを書こうと思います。(実際のコードのレベルでは「えいや」でルールを決めてしまいましたが。)
何が問題かというと、
- 順番も有無も任意に決められ、かつお互いに階層関係にないパラメータで決定されるリソースの URI へのマップ
です。
例えば書籍の中では、2値によって決まるリソースとして緯度、経度が出てきますが、このときはカンマで区切ることで一つの位置という情報を表現していました。(typo で ; になっているところが何カ所もありますが、カンマになっていないと意味が通じません。)
/Earth/43.9,-103.46/...
このパターンは
- 「緯度経度」の順番
- 緯度、経度ともに欠けることがない
であり、比較的単純にルールを決定し、URI にマップすることができます。
しかし自分の作っていたリソースが
- A, B, C の3つのパラメータを持ち、それぞれ意味が異なる
- 3つはそれぞれあってもなくてもよいが、全部ないとさすがに困る
- 個々のパラメータに階層関係はない
というもので、簡単に言うと従来の Web では
?a=VAL1&b=VAL2&c=VAL3
という query string で表現されるものです。無理矢理階層を割り当てて
/VAL1/VAL2/VAL3
としても、VAL2 は別に VAL1 に属しているわけではありませんし、順番が関係ないからと言って
VAL1;VAL2;VAL3
にすると、今度はこの順番が入れ替わると意味が分かりません。では順番を保持させるべく
VAL1,VAL2,VAL3
なのかというと、……何度も書いてますがこの順番には特に意味はありません。ただどれが何のパラメータなのかを判別するために順番を守ってくれないと困る、というだけのことです。
これは…そもそもリソースがなんだか分かっていないってことなんですかねぇ?
イメージとしては以下のように三次元の座標軸上で考えられるのかなと思っています。
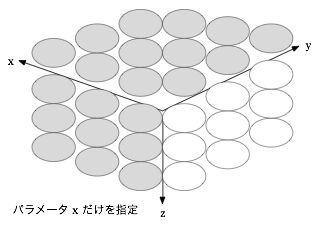
- パラメータが1つの場合はその軸とそれを回転させた立体のデータ
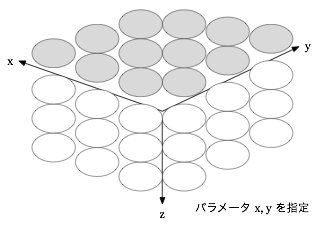
- パラメータが2つの場合はその2軸で作られる平面のデータ
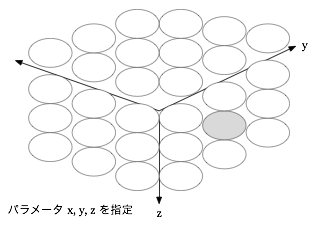
- パラメータが3つの場合は3次元上の1点
という感じで徐々にリソースが限定されていくような感じ。もちろんパラメータが本当に3次元を表現していて、それぞれ x, y, z なのであれば順番は自明ですが、実際にはこの順番が自動的に決定しないというものです。
これは、どう考えるのがよいのでしょうか? やっぱリソースがなんだか分かってないのかなぁ? 適当に順番決めてカンマで区切るのが無難なのかなぁ? さすがにパスがないのはダメだけど、カンマ区切りのパラメータの一部がないのは問題ないからなぁ。デキのよくない、引数の多い関数を作るみたいな感じでちょっとイヤだけど。
まぁどっちみち Python 依存なんだけど。
userdir の場合に限定すると、
- 対象となる CGI およびそれが収まっているディレクトリの owner が本人
- またそのディレクトリおよびファイルが owner 以外に +w になっていない
ことが条件。
user の部分以外は 6 以上の permission(writable)は許可されない。
755 とか 644 かそれ以上に厳しい permission にしなさいと。module mode の PHP に慣れちゃうとつい忘れる。1つーか Apache.org の配布では標準では disable なのよね、これ。Debian がデフォルトで enable になってるから戸惑ったのか。複数の環境を使うのって勉強になるな。
module mode の PHP では
secure mode を設定する。secure mode はどの程度 secure にするか細かく設定できるので、例えば普段の開発は緩めに、動作検証ではきつめになどの設定変更が可能。まぁそれ言ったら Apache の設定次第で CGI の動作も変わるんだから同じっちゃ同じなのか。開発環境は普段 suExec が disable の方が使いやすいのかもな。
CGI モードの PHP なら同じ制限になる。 ↩
- 思ったより情報が少ない
- CPAN にはたくさん登録されているが、FreeBSD の ports, Debian package で探すと以下の3つしかない。1perldoc.jp にも以下の2つしかない。
- HTML::Template
- CGI::FastTemplate
- Template(template-toolkit.org)
HTML::Template
- 独自タグ <TMPL_VAR> を使う
- HTML タグの中に HTML タグを書くことになるのだが、エディタで見ている場合はともかく、WYSIWYG ツールには優しくない気がする。
- 特に顕著なのは属性の値をこれで与える場合。NAME="VAR" の "" は書かなくてよいので、そういうルールで運用しておいた方が無難。2
- 内容をセットしない変数の部分は出力されない。この動作はいい。
- このモジュールで output() しても実際には STDOUT には出力されない。結果が返ってくるのでそれを print する。なんか意外な動作。
- テンプレートの中にロジック入りまくり。
<TMPL_LOOP>
<TMPL_INCLUDE>
<TMPL_IF>
こういうテンプレートの方が人気が出るが、これはテンプレートの役割として謳われているロジックとデザインの分離が果たされていないということをみんなあえて無視しているんだろうか? つーか文法が2つもあったら邪魔くさいじゃん。文法は Perl だけにしようよ。
キャッシュはあるが、HTML::Template::JIT を使うとさらに高速化できる。ただし、コンパイルは遅い。
CGI::FastTemplate
Fink には入ってなかった。
- 変数は Perl の文法に従い $VAR と書く
- 正確には以下の正規表現にマッチするものに限る。(UPPERCASE に限るってちゃんと perldoc に書いてほしいなぁ。)
/\$(?:([A-Z][A-Z0-9_]+)|\{([A-Z][A-Z0-9_]+)\})/
- 内容がセットされなかった変数の部分はそのまま $VAR と表示される
- HTML である必要はない
- 正規表現でパースしている
- man では eval を使っていないから速いという話
- 単純な正規表現パースなのでテンプレートにロジックを入れられない(Good!)
- CGI 用に content-type ヘッダを自動で出力はしてくれない
- strict() メソッドで parse エラーを STDERR に吐き出すことができるので、Web サーバのログを利用しながらテンプレートのデバッグができる
- if や loop などのインテリジェントな機能はない(テンプレートにロジックが書けないだけじゃなくて、そもそも機能としてない)
- loop は苦肉の策で loop 部分だけ別のテンプレートに分割してそのテンプレートの parse 結果をスクリプト内で loop して連結させるという方法を採る。loop の数が1つだけならいいかもしれないが、list 1つ、table 2つとか言うテンプレートになるともう扱いがかなり面倒な気がする
本格的な運用には難しいような
template-toolkit.org
かなり柔軟な処理ができるらしい。
CGI には限らず使えて、変数は [% var %] で書く。INTERPOLATE オプションをつければ $var と書ける。(FastTemplate と違って小文字で ok)
- 変数名はブロックの単位でハッシュ変数を割り当てるとかなり分かりやすいものにできる。
- ハッシュのハッシュでも ok
- [% %] の記述であれば、という制限がつくと思う(まだよく分かっていない)が、テンプレート内に制御構造をバリバリ書ける。
- 考え方によっては [% %] でループなどのブロックを、$ で変数を書ければよかったんじゃないかなぁと思うんだけど、どうもそうはなっていないらしい。
- 個人的には独自タグ方式よりまだマシに見えるけど、まだテストが必要ですな。
また Extension の対応が変わった。いちいち変わりすぎ。もう少し考えて作れないのかな。Extension 作者、Theme 作者もよくいやにならずに追随してくれるよ、ほんと。というわけで使えない Extension がまだまだあるので 1.0 PR はやめにした。Security Fix なら 0.9.4 出してくれればよかったのに、まったく。
Mozilla Seamonkey の動きを見ればきっと 1.0 以降も似たような話は絶えないだろうなって感じがするけど、Firefox の成否のカギは Seamonkey から何を反省したかってのもかなり大きいと思う。
例えば Extension は Firefox を使ううえでのキモみたいなもの1なんだから、もう少しうまく扱えるようにすべき。Extension の仕様は分かっているんだから、インストーラの段階で対応しているかどうか調べられる仕組みを作れないのか。(簡単ではないと思うが。)
そして Security Fix をどこまでバックポートするかというのもきちんと判断する必要があるだろう。Firefox が単なる Technology Preview でなく Mozilla Foundation の Product という位置付けになれば、非互換の部分がたびたび発生するのはまずかろう。これが単なる Extension でなく業務に使えるレベルの XUL アプリだったらどうする。Security は気になるが XUL アプリの対応ができていないからアップデートできない、ってことだって十分にあり得る。それじゃ IE と同じだ。Microsoft 様と同じことを弱小 Mozilla Foundation がやったらそりゃ勝ち目なんかない。
今回の方法(0.9.4 ではなく 1.0PR をリリース)が 1.0 ゆえの緊急避難であったことを望む。
あ。Extension および XUL アプリのアップデートチェッカが Firefox に依存せずに単独で動くとだいぶいいかも。少なくとも Extension が対応してなかったからアンインストール → profile 飛ばし → ダウングレードインストールの流れは要らなくなる。まーでも security fix はある程度バックポートするってのがまず基本じゃないのかな。
リリース時点では余計な機能を積まずに軽くしておき、必要な人が必要な機能を追加できる。 ↩
gzip が 30MB の Apache のログを一瞬で 2MB にした。もっと速く使っときゃよかった。非力な DOS 時代のイメージじゃあかんですな。