まとめ
- AWS の Policy の種類が復習できた
- AWS の Policy 関連用語と Terraform 用語の Resource, Data Source 用語との紐付けができた
- 静的サイト向けの Policy に集中して考えた
操作から切り離して概念を整理しやすいのでドキュメントベースになるとありがたい。
AWS S3 の Bucket を読み書きできるポリシーとその適用方法が揺れていた
これまでに存在しているポリシーが以下のようなひどいことになっていた。
- S3 の Bucket Policy で Role と Action を割り当てているもの
- S3 の読み書きに特化した IAM User を作り、そのインラインポリシー ( IAM User Policy ) 側に Bucket ( arn ) 情報が書かれているもの
- IAM User Policy Attachment ( 未適用 )
図にするとこんな感じ。
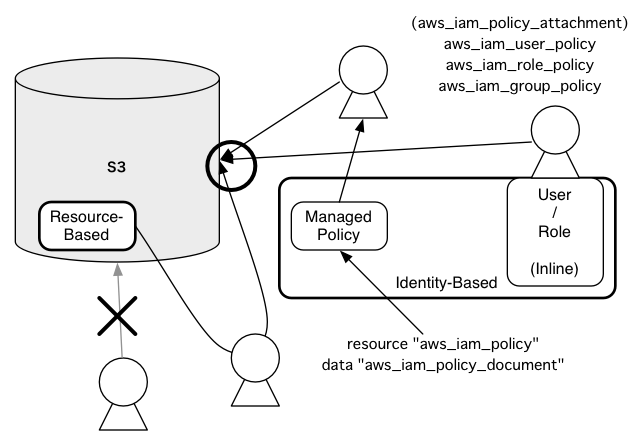
※ 上の図では AWS 用語を枠線で囲んでおいて、Terraform 用語を無地の上にそのまま置いている。そもそもこれまでこの辺の用語の理解が曖昧だったことに今回ほんとに気づかされている。(どうしても触る機会の少ないインフラ周りがおざなりになってしまう。)今回気づいたのは Bucket でも User でもない真ん中の Managed-Policy を aws_iam_policy で管理するようにしたらどうか?という話。
初期は 1 でやっていた。この頃の目的は静的サイト向けの Bucket ではなく、Web アプリの無限ストレージとして使い始めた。まだ AWS 自体がよく分かっておらず、読み書きを割り当てている IAM User の概念もボンヤリしていた。
で、いくつかそういうアプリが増えてきたときに Bucket 作って Policy 開いて、みたいな操作がダルくてイヤになって、Policy だけ別に作って Bucket に適用した方がよいのでは? と思い始めて 2 の形になった。
しかしこれは今にして思うと失敗だった。たぶん当初 3 を意識していたがやはり操作が面倒くさくて 2 の形に流れてしまった。
しかもこの形での指定が妙に複雑になっている部分がある。確か
- ログイン可能な IAM User が手動で読み書き可能な Bucket を確認できるように
- Rails + fog で bucket を覗く際になぜか指定が足りないと怒られた
辺りが理由と記憶しているが、これは静的サイトを CI で deploy するようにという今回の目的のためには不要な配慮になるはず。
解決案
静的サイトに限定して考える。
上のポリシーは Web アプリのストレージとしての Bucket のポリシーと混ざっているのがそもそもよくない。
AWS のマネージメントコンソールを手作業でぽちぽちしていくやり方と Terraform を共存(怖いけど)させる場合、恐らく 1 の形に近づけて Policy を Data Source で定義したうえで、せめてコピペせずに Bucket ごとに 個別に割り当ててあると直感的に分かりやすいと思う。(Bucket のプロパティを覗けばどういう状況か分かるので。)
ただ、ちゃんと自動化するなら第4の方式、
- S3 Bucket
- IAM User
- IAM Policy
- IAM Policy Document
をそれぞれ独立して定義した上で IAM User に IAM Policy をアタッチしておいて、最終的に IAM Policy Document だけをメンテすればよい感じにする方が .tf も .tfstate も diff が小さくなると思う。
少なくとも IAM User Policy の側に Bucket (正確には arn)を列挙してしまっている現状は、手作業での手間は若干減ってはいる(少なくとも bucket ごとに丸ごと policy をコピペしたうえで書き換える必要はない)が、自動化前提ではアホくさい。
User の関心事は 1) シンプルに静的サイトの deploy であり、2) deploy は手作業でなく CI/CD サービス経由であり、3) ログインは不要であるならば、 ユーザーの知っているべき情報は特に変化はない 。
手作業を捨てるならコードは DRY にして設定ファイルとしての HCL の可読性に寄せる方がスジがよいと思われる。
要確認
そもそも CloudFront 経由でしか publish しない方針なら、実は S3 の Read Only Policy って必要ないのでは?
参考
- IAM ポリシー - AWS Identity and Access Management
- AWS IAMポリシーを理解する | Developers.IO
- AWS: aws_iam_policy - Terraform by HashiCorp
- AWS: aws_iam_policy_document - Terraform by HashiCorp
- 【基本おさらい】Amazon S3バケットに読み取り専用のポリシーをつけたAWS IAMポリシーをサクッと作る方法 | Developers.IO
- S3のアクセスコントロールが多すぎて訳が解らないので整理してみる | Developers.IO
公開されるどこにも記録を残していないような気がするが、2016年の初めからとある事情により JavaScript のエラーをサーバに送りつけて監視サービスに送りつけてエラーの発生を知り、修正する、ということを地味にくり返していた。
そこに至る顛末と今後の分析の予定のお話。
背景
これまで扱ってきたものはそこまで JS ヘビーでないものが多く、また自分で書くものはできるだけユニットテストが動くように書いていた and そもそも監視サービスが入っていなかったので、エラーのログをサーバに送るとか監視するとか、そこまで手をかけていなかった。
しかし今回の案件は初期の設計では考えてもみなかった量のカウボーイスタイル JS がコミットされしまい、要するに非常にイキのいいフレッシュなレガシーコードがてんこ盛りで動いている状態になってしまった。
(あーはい、全部ぼくがコードレビューしてリジェクトすれば防げたんです、すいません。それをやったら別な角度からこっぴどく叱られたのでしょうけど。)
まずは静的解析
CI に乗せるまでも苦労したのだが、CI に乗せたのを機に eslint は動くようにしていた。
その段階ではほぼ致命的な問題は見つからなかったので、ちょっと安心していたのだけれど、やはり自動化されたテストのないコードが増えると厳しい。「なんかうまく動いていない感じがする」「再現性を確認できるレベルの報告は来ないが、何かは起きてるっぽい」という状態であり、またこの状態では積極的にはやりたくないが、どうしても変更はせざるを得ない。(完全無欠で変更不要なコードなんてあり得ない。)
cache busterできていない問題
そもそもの話なんだけど、件のサイトは AssetPipeline 的な仕組みが標準で入っていないので、当然のように JS がキャッシュされて、ブラウザによって動作がマチマチになってしまう問題を抱えていた。Rails 界隈では AssetPipeline 批判がすでに一周回り終わってしまっているが、世間にはまだそのような便利な仕組みがあることさえ知らずに素朴にキャッシュの効く生 JS を書くお仕事もあるわけです。はい。
が、なにせ量が多く、納得のいく形の cache buster まで持っていく時間を捻出できないので、そこは無視することにした。「cache の問題で意図した動作がユーザーの手元で再現できない場合がある」ことを記録するに留めることとした。
ガッデム。1
とにかくwindow.onerrorでサーバに送る
以前ならテストコードのないサーバサイドのアプリもエラーログで追い詰めつつ改修していくというのも割とよくやったが、最近はそういうやんちゃなコード扱ってないし、そもそも JS だとエラーログねーし…と思っていたが、「いや、何かで見たな」と思い返し、考え方を変えて、「まずはよく分からない状態を分かるようにする」ことにした。
大手Webサービスがクライアント側で発生したJavaScriptのエラーをどう収集しているのか まとめ - Qiita
を参考に、いちばんざっくり書けそうなのは
- window.onerror
- Ajax(サーバサイドアプリは単独ドメインなので)
の組み合わせで、サーバサイドに送ってサーバ側で NewRelic に送ることかなと考えた2。サーバサイドのエラーはすでに NewRelic に送ることができていたため、サーバ側に来てさえしまえばなんとかなると考えたのだ3。
NewRelic なら Error rate が基準(デフォルトでは 5.0%)以上になると通知してくれるので、何かが起きていることは可視化されやすいし、そこには
- URI
- ソース上のエラー発生箇所
- エラーメッセージ
といった基本的な情報が含まれているので、「分からないものが分かるようになる」段階としてはひとまず十分と言えるだろう。
びっくり仰天サーバサイドでJavaScriptリテラルを生成するコードの存在
上の記録をやり始めてから明確にエラーが減り(JS側の動作がおかしくてサーバ側にエラーが起きていたものも含む)、喜んでいたのもつかの間、いちばんショックなコードに出くわした。
ざっくり要約するとサーバ側のテンプレートで
var obj = val1 + {{$val2}};
みたいなことをやっているので、サーバ側で $val2 が null になると JavaScript 実行時には
var obj = val1 + ;
みたいなコードになってしまい、SyntaxError になるというもの。
こ れ は ひ ど い
2015年のコードでこれはないよ。値は HTTP か data-* で渡せよ。eslint 意味ねーだろ!!
サーバサイドでJSの変数直埋めするなよー。HTTPかDOMで渡せって。JSのlint意味ねーだろ。
— wtnabe (@wtnabe) November 22, 2016
泣く泣く
{{}}
の中に条件演算子を埋め込んで回りましたとさ…。
※ サーバサイドの View で JavaScript を書くのをそもそも禁止すれば少しはマシになりそうな気がするんだけど、これを静的解析で見つけることは可能なのかなぁ? 人間がダメ出しすることはできても機械的に弾けないとやはり不安は残る。
無視すべきエラーとGoogle Analyticsへの記録
最近あった、ちょっと困ったパターン。
- Chrome 55 で実装された PointerEvents がバグっててエラー急増
- Babel を使って書いてる部分があって、IE 8 以下でエラーを吐く
- iOS の Google Search App が(恐らくZoomイベントに)バグを抱えていてエラーを吐く
こいつらはブラウザ側の問題でかつサポート外か、警告は出るが動作はするというものなので、無視する(サーバに送らない)ことにした。
※ Google Search App だとググってからでないとサイトを訪れることができないので、ほぼ production 環境以外ではデバッグできないわけだけど、みんなこんなもんどうやって相手してんの?
無視するだけだと怖いのでGoogle Analyticsに記録することにした
もしかしたら Chrome 56 で修正されるかもしれないし、闇雲に無視してしまうのは本来拾えるはずの情報を捨てることであり、なかなか怖い。ということでアプリが動いているサーバには送らないが Google Analytics には送ることとした。これなら通知はされないがあとで記録を見返すことはできる。
Google AnalyticsでJavaScriptエラーをトラッキングする
ただし、記録、閲覧できる情報量に不満があるので、もしかしたらイベントの方がよいかもしれない。
Google Analyticsを利用してクライアントサイドのエラーのレポーティングを行う - Thousand Years
とは言え、だいたい普通はイベントに関しては「何らかの効果の捕捉」に使うもので、利用回数に制限のあるイベントトラッキングを、何かの拍子に爆発しかねないエラーの記録に使うのはややリスキーだよね。
Google Analytics は分析目的の詳細な情報の記録ではなく、あくまで数の参考に留めておくのがよいのかもしれない。
まだ改善は続く
自分以外の人間が書くコードに対して、自分の得意なテストコードベースの手法だけを適用していこうとするのはやはり無理がある。一朝一夕には TDD はできるようにならないし、自社に十分な人数のデキるエンジニアが揃っていない場合は理想だけを追っても意味はない。
ということもあって、エラーログを単に「現在エラーが起きている」ことを知るためだけに使うのではなく、エラー発生率の変化など、指標として可視化してふり返りや分析にも利用できるようにしたらどうだろう、そしてたぶんこれは単独のサイトで考えるのではなく、会社全体としてログ分析基盤の一環として考えるべきなのではないかと思い始めている。
NewRelic以外のログ分析の基盤を用意したい
と考えると、単なる尻拭い案件ではなくなり、急に面白みが増してきた。
ERRORログが多すぎるWebアプリに出会ったら | GMOインターネット 次世代システム研究室
なんて話もあるが、現在我々には
Amazon Athena – サーバーレスのインタラクティブなクエリサービス – AWS
があるので、ログを S3 に放り込んで Athena で分析するのはアリだなと考えている。
NewRelic はエラーの通知とグラフィカルな可視化にはよいが、そもそも NewRelic のサイトの応答が重く、Error も Similar なもので畳まれて追いにくくなるので、もっと分析に特化したものは用意した方がよいように感じている。NewRelic はすぐに対応するにはよいが、長いスパンで見たい場合にはあまり向いていないなーと思っていたが、似たようなことを感じている人がいた。
※ export も自分で API を叩くコードを書かなきゃいけないし。
なぜ私たちはSumo Logicを捨ててBigQueryを選んだのか - tech.guitarrapc.cóm
この記事では BigQuery に入れることにしたようだが、自分には基盤整備の時間が十分にあるわけでもないので、「とにかくなんでも後回し」で考えると S3 + Athena かなという気がしている。幸い、ログを S3 に保存するのは自動化できている。
※ ところでバックトレースは複数行にまたがってしまうのに行に対して検索を掛ける SQL ベースの分析基盤はエラーログ分析には実は向いていないような気がしないでもないのですが、すでに基盤を構築済みの皆さんはどうしてるんですか? トレースを改行のない状態に畳み込んでから記録してる? そうするとロガーに手を加える必要がありますよね?
ログの情報量アップ
これまでは window.onerror に標準で渡ってくる情報を頼りに、トレースを取らずにそのままサーバに送っていたが、さすがにつらくなってきたので、
JavaScriptエラーログ収集に役立つツール・ライブラリ・手法まとめ - WPJ
を参考に
StackTrace.JS - Framework-agnostic, micro-library for getting stack traces in all web browsers
や
を使ってバックトレースは欲しいと思っているところ。
全体的な目標としては
JavaScript 祭で発表してきました - 若き JavaScripter の悩み
こんな感じですよね。よくまとまっていて分かりやすい資料をありがとうございます。
バグを防ぐ、デバッグという意味では本稼動してるアプリのログはやはり後手に回っているので、本来は前行程で防ぎたい。でも今は便利なツールが揃っているし、後手に回ったなら回ったなりにできることはいろいろあるし、これに慣れてくると、ちゃんとログ残したり監視できていないサイトはデプロイするの怖いという気もしてきそう。
エンジニアは怠惰で贅沢な生きものだもの。
いつものことながらすごく今さらな話。
ずっと ruby-mode.el 一本でやってきたのだけど、Rails のコードはどうも読みにくいし、なんかそう言えば rails.el って聞いたことあったなぁと思い出して調べてみた。結果、
- rails.el は 2007年で止まっていて事実上の discontinued 状態
- Rinari という minor mode があるらしい
minor mode で大丈夫なんかいなと思ったけれど、心配無用でした。1
Rinari
Rinari: Ruby on Rails Minor Mode for Emacs
インストールの注意点
git clone を使って install する際は submodule を要求する。default では git protocol で取得しようとするので git protocol の通らない環境ではインストールに失敗する。
..gitmodules を編集してから submodule を取得しにいけばいいのかもしれないけど、やってみてないのでよく分からない。
Rinari がやってくれること
Introduction - Rinari: Ruby on Rails Minor Mode for Emacs
- navigation ( MVC や migration 間の行き来 )
- Web server 立ち上げたり
- 適切な sql-mode を起動したり
- テストを支援してくれたり
など。あれ、「読みにくい」という問題は解決しないような。
Rhtml-mode を追加
「読みにくい」のが始まりなので追求。
Add Ons - Rinari: Ruby on Rails Minor Mode for Emacs
んーでも YAML も CSS も JavaScript も困っていないので、追加するとしたら Rhtml かな。
あと yasnippet-rails を入れておいた。(yasnippet はインストール済み)
rhtml-mode の色づけがちょっと気に入らなかったので
M-x customize-group
で
erb-faces
からちょっといじった。
(custom-set-faces
...
'(erb-delim-face ((t (:foreground "blue" :weight bold))))
'(erb-exec-face ((t (:inherit erb-face :underline t))))
'(erb-face ((((class color) (min-colors 8)) (:underline "black"))))
'(erb-out-delim-face ((((background dark)) (:foreground "blue" :weight bold))))
...
こんな感じ。
結局 Rails のコードは読みにくいまま
..html.erb は編集しやすくなったし、コード間の移動もやりやすくなった。しかし Ruby のコードは読みやすくならなかった。
Rails のコードはなんていうか helper 以外は宣言的(?)過ぎて、普通のコードのようにメソッドのカタマリを目が認識できない。そのせいかどこで何をやっているのかよく分からない感じになってしまう。少なくとも古い Ruby コードにしか馴染みのない人間にはいささかつらいものがある。もしかするとこれが DSL と騒がれた片鱗なのかもしれないが。
とりあえず何かのツールで劇的に読みやすくなるということはなさそうなので、少しずつ目を慣らしていくしかないみたい。
とは言え Rinari は便利。収穫アリ。
ほんとの最先端は Rinari じゃないらしいんだけど、ほとんどのツールで先端を追ってない自分にはまったく問題ない。 ↩
Rake の練習課題として以前調べておいた
を試そうかと思っていたんだけど、ちょっと調べたら
を見つけた。こっちの方がいいかもしんない。
rote は
- Textile などで書かれたコンテンツファイル
- メタデータを記述する rb ファイル
が分離していたんだけど、webby ではこれが一つのファイルにまとまっている。フォーマットはこんな感じ。
---
RFC822 風のメタデータ
---
Textile などで書かれたコンテンツ
コンテンツの処理は filter で指定する。filter には Textile などの書式の他に erb も指定できるので、コンテンツの中に Ruby で扱える変数や処理を自由に埋め込むことができる。これは便利だ。
使い方
Rails のように webby-gen コマンドでサイトのひな形を作る。このとき指定できるのは 0.9.3 で
- blog
- presenation
- tumblog
- website
の4種類。それぞれ適した task が利用できるようになる。
blog
試しに blog を作ると task に
blog:post
ができて、これを呼ぶと呼んだ当日の年月のディレクトリを
YYYY/MM
で掘る。blog:post 時に path の入力を求められるが、これを入れて
YYYY/MM/path
なエントリになる。Type Pad 風というか海外の blog ツールで最もポピュラーな URL かな。
website
これが website になると
create:page
になる。
deploy
Capistrano ではないけれど rsync などを使った deploy も行える。ただし ftp では行えない。うーん、もったいない。ftp に対応すれば使えるシーンはたくさんありそうなのに。ま、output したものを sitecopy などで mirroring すればいいっちゃいいんだけど。
autobuild
面白い機能として最後に autobuild を紹介しておく。このタスクを実行するとファイルの更新を監視して自動的に HTML の出力を行ってくれ、なおかつ WEBrick で serve してくれる。
正直、このツールに興味を持つ人は自分で Web サーバくらい立てられる気もするが、そうでない人でもこの autobuild を利用すればサイトの検証を行いやすい。
※ コメントを読んでもらうと分かりますが、以下の文書は今のところリンク先の文書とかけ離れた話になってしまっています。削除してしまうのが簡単なのですが、なんかそれもどうかなと思い、リンク先の文書とは切り離して残そうと思っているところです。ということで、この文書はとりあえずリンク先の文書とは切り離してお読みください。あーあ。やっちまった。
otsune さんのブックマークより。
時代の流れに沿って印刷、出版業界も仕事のやり方や提案の仕方変えなきゃね、というだけの内容なのに、中途半端に聞きかじった知識で本論よりも紙幅を割いて Web やネットを批判しないとやってられないのかな、と心配してしまう書き方になってますな。
まぁネット界隈というか Web 界隈のビジネスや試みでは、激しく動いてはいるが商業的に失敗してる試みも多く、そういう意味では「何やってんだこいつらは」的な印象を、紙を含め、ネット以外のメディアの人は抱きやすいだろうなとは思う。でもそこは成熟しちゃったメディア業界と違うのは当たり前だし、また、Web 系のビジネスは小さい初期投資で始められるものもあるという特徴もあるのだから、今の時点では失敗したときの痛手も既存のメディア業界と全然違うと言っていいと思う。つまり、従前のメディア業界の人たちの感覚では Web 界隈の人のアクションを批判しない方がいいですよ、と思うんだけどどうだろう。1
もっとも、「いずれ取って代わられる」的な発言が鼻につくのは事実で、売り言葉に買い言葉的な、脊髄反射的な反応が生まれる下地を Web やネット界隈の人たちが作っちゃってる部分はあるので、それ以外のメディア関係の人たちのそういう反応を見ても差し引いてあげないとダメかもしんないけど。
印刷、出版関係は放送業界と違って下手に自分たちもコンピュータを使ってる人たちって意識がある分(?)謹慎憎悪みたいな状況に陥っているように見えるフシが多々あるんだよな。 ↩
shugo さんとこ 経由で trac
いいかも。でも Subversion 使ってないし、Wiki とか日本語通るんでしょか? まったく新規に起こすならこれよさげだなーと思うんですが。
何がいいって Repository の Web インターフェイスもあるけど reStructuredText. このフォーマットが唯一メールなどのプレーンテキストにそのまま使い回せるフォーマットだと信じているので。いわゆる Wiki フォーマットは書くのは速いけどそのままメールにコピペできないのがつらい。そら技術的にはできるけど、それを読むのはやだ。
まー普段の作業と再利用とどっちの優先度が高いかって言ったら前者かなぁとは思いますが、使い回すときって「メールで確認とかって事態で、何度も再利用するのが容易に想像される」ので、そのままコピペしたいのですよ。
参考。
昨日のメモ書きを眺めていてふと PCRE のバージョンが気になった。手元の環境では
| PHP | PCRE |
| 4.2.4-dev | 3.4 |
| 4.3.10 | 4.5 |
になっている。PCRE の ChangeLog によると
- 3.3 で utf-8 サポート開始
- 3.8 で
The experimental UTF-8 code was completely screwed up. It was packing the bytes in the wrong order. How dumb can you get?
PHP のマニュアルによると Unix 版は 4.1.0 から、Win32版は 4.2.3 から utf-8 サポートが有効になっているらしい。
PHP の ChangeLog によると
| PHP | PCRE |
| 4.3.5 | 4.5 |
| 4.3.3 | 4.3 |
| 4.3.0 | 3.9 |
| 4.2.3 | Win32 で utf-8 対応を有効に |
| 4.0.5 | 3.4 |
ということなので、4.3.0 以降は preg で utf-8 使って大丈夫と判断していいかな?
http://member.nifty.ne.jp/poseidon/emu/sheepshaver1.html
from スラドの http://slashdot.jp/comments.pl?sid=144358&cid=462976
へぇ。PPC エミュレータ。要 Mac のシステム ROM。
8.6 までの MacOS が動くそうで。十分じゃないですか。動かしてみてないのでスピードなどの使い勝手は分かりませんが、PPC で 8.6 ならけっこういろんなアプリが動くし、スピードはプロセッサメーカーがある程度勝手に問題を解決してくれるので、これはかなりいいかもしんない。
もちろん OS X に移行できる環境ならそれがいちばんいいですが、古い環境を残しておかなければいけない、でも機械は古いし遅いし、そのくせ場所取るし、、、という状況には向いているでしょう。(かなり限定される気もするけど。)もちろん遊びにも向いているし、Web なんかのマルチプラットフォームを常に意識する状況にも向いているなぁ。(古い PCI Mac なんかけっこうお手頃価格で手に入るだろうし。)
Perl が今のところネイティブな言語である自分には、PHP はイマイチ自由が利かないとやはり感じてしまう部分がある。
その一つはコンストラクタが値を返せないこと。これができないとインスタンスの生成について失敗を示す偽を返すことができない。でもこれが OO の基本的なスタンスなのであれば仕方がないので別な方法を考えた。
これはたぶんさらに異なる言語を扱う機会が出てきても通用する。Perl 脱却へのさらなる一歩でもあるわけだ。
面白い時期に今の会社に入ったものだと思う。もちろん社員全員やる気があってこれから伸びるぞ、などというあほな意味ではないが、価値観のギャップを埋め込むにはいいタイミングかもしれない。暗躍は得意ではないが、そうも言っていられない。潜行するには自分の価値観を早く固めてそれが熱く語るようなシロモノではないくらいに自分の中で消化する必要がある。年内にビジョンは固めておくか。
先日の飲み会で小便器のことを「朝顔」と呼んだところ、誰にも通じなかった。そこで調べてみた。
http://www.lint.ne.jp/~takuya/wc/wc111.htm
うーん、普通に見かける小便器は朝顔ではないらしい。
っつーかそういう話じゃないんだけども。通じなかったことのショックがことのほか大きかったです(笑)