考えるのが面倒で避けてきた日本語ファイル名を含む (V?FAT|NTFS) 領域の mount についてやっと分かってきたので整理。
※ 例によって嘘八百書いている可能性があるのでツッコミ希望1。
まとめ
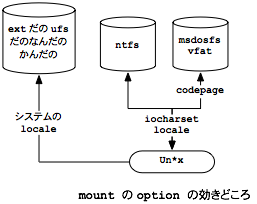
- mount の option で与える charset/locale は、mount する領域のファイル名のものではなく、「これに変換して扱う」という意味
- 環境変数の言語設定に暗黙に従うのだと思っていたけど、これがそもそも間違っているらしい
- ntfs の場合、ファイル名の保持は必ず Unicode(utf-16le?) で行われるので、codepage を指定する必要がない2
- 恐らく iocharset/locale の設定によらず、ファイル名そのものは見える
- つまり設定ミスに気づきにくい
- → ext3 や ufs の領域にコピーしたらファイル名が読めない!という事態に
- Windows を使っていてファイル名が SJIS に見えるのは Windows の API を経由したときに変換されているのか?
- msdosfs/vfat の場合は fat 領域の codepage を指定するオプションがある
- この codepage が DOS/Windows のバージョン(≒言語)によって異なる
- 従って codepage が正しくセットされていないと日本語ファイル名が読めないという状況になる
- → 逆に言うと日本語ファイル名が読めなくなることで mount option が間違っていることに気づきやすい
- vfat も long filename の部分は Unicode で、short filename の部分で codepage を使う、という構造になっているらしい
オプションの記述方法
例えば日本語EUCの場合
| locale | ja_JP.eucJP |
| charset | euc-jp |
codepage については共通のはず。
FreeBSDの場合
| FAT | -L ja_JP.eucJP -D CP932 など |
| NTFS | -C eucJP など |
ntfs の charset は eucJP などのように書くらしい。euc-jp じゃないのか? locale の方になんとなく合わせてある? つか FreeBSD で charset つったらそういうもんだっけ。
FreeBSD 6.1-R の時点で、標準で利用できる mount ではマルチバイト文字を含むファイル名で書き込みはできない。
Linuxの場合
| FAT | -o iocgarset=euc-jp,codepage=cp932 など |
| NTFS | -o iocharset=euc-jp など |
実際には使うドライバ?によって違う。Linux の場合は ntfs を mount するためのツールがいっぱいあるので、それによっても変わってくると思う。(ますます面倒くさい。)