Cloud TasksとActiveJobでバックグラウンドジョブをこなす

前置き - このセットの選択理由
やや長くなってしまうが、なぜ Cloud Tasks なのかについて備忘録も兼ねて書いておく。
なぜフルマネージドサービス寄せにするのか
一言で言うと生のサーバに近いホスティングでない場合、Solid Queue 以前のワーカープロセス + なんらかの(メモリストア含む)ストレージ方式は急にコストが大きく膨らんでしまうから。だから例えば Google なら Cloud Compute Engine を利用している場合、この限りではないと思う。
- そこまで利用頻度の高くないバックグラウンドジョブに対して HTTP リクエストと同様にインスタンス(コンテナ)を割り当てるのはコストパフォーマンスがよくないし、安定稼働を気にしなければいけないプロセスが増えてしまう
- 従来よくバックグラウンドジョブキューに使われていた Redis について、Google Cloud はもともと Heroku のようには小さい単位で利用し始めることができず、丸ごと VM インスタンスが必要になってしまう1ので、上記のワーカー用のインスタンス(コンテナ)とは別にさらにインフラが必要になる
※ 生のサーバに近い構成のホスティングの場合、Worker は単なる Redis プロセス + アルファかもしれないが、Web 専用のホスティングやコンテナに特化したものの場合、Worker は Worker で別料金になりやすい。
inlineやasyncではダメなのか
そもそも別プロセスに回すからコストが高くつくのであって、そのまま処理できるならそのまま処理した方がよいのではないかという指摘があるかもしれない。が、これは場合によるとしか言いようがない。
まず処理の時間に問題がない場合、別に inline でもよい。例えば ActionMailer でメールを1通送る処理などは、従来2はわざわざバックグラウンドジョブに割り当てずにそのまま送っていた。ただこれが 1通で収まらず、送信元の人に1通、相手に1通、管理者への通知用に1通送りたいですとなったら3通、ごく単純に考えると処理の時間は3倍近くに膨れ上がる。これをそのまま inline で処理してよいだろうか? ActionMailer くらい inline でよいのでは? とは断言しにくい。
では async ではどうか? 確かにユーザー側の待ち時間については解消できる。ただ、HTTP POST から何らかの情報を記録して通知まで行いますという処理は、関係者にとって大事なことだからその処理を行なっているわけで、その処理の途中で失敗したのでユーザーにリトライをお願いするといったことは基本的にはあってはならない3。例えば thread で処理しているVM(コンテナ)が何かの拍子にメモリ不足になった場合どうするか? async では retry できないので、async でええやんとも言い難い。
※ これらの判断は自分が実際に sucker_punch で扱っていたジョブが飛んで一部のメールが送信されなかった経験を持っているので慎重になっているから、ということでもある。
なぜCloud Pub/Subではないのか
Google Cloud でジョブキューを担ってくれる上記の課題に対応できるフルマネージドサービスとしては Cloud Tasks のほかに Pub/Sub がある。公式に比較用のドキュメントがあるので見てみると、
Cloud Tasks か Pub/Sub かの選択 | Cloud Tasks のドキュメント | Google Cloud
- Cloud Tasks は HTTP を通じてタスクを渡す前提であり、Webアプリケーションフレームワーク(eg: Rails)と相性がよい
- Pub/Sub は Publisher と Subscriber が非対称なので、Subscriber 側に追加の設定が必要になるが、Cloud Tasks は Publisher が Handler を明示するので、例えば Rails の中に閉じて処理することを考えると設定が減って扱いやすい
- 性能的には Pub/Sub の方が上だが Cloud Tasks も 500 QPS は処理できるので、これで十分なら Pub/Sub に寄せる必要はない
500 QPS を超える処理を Rails で全部やりたいかというと、どうなのかなという気がする。
Pub/Subについて補足
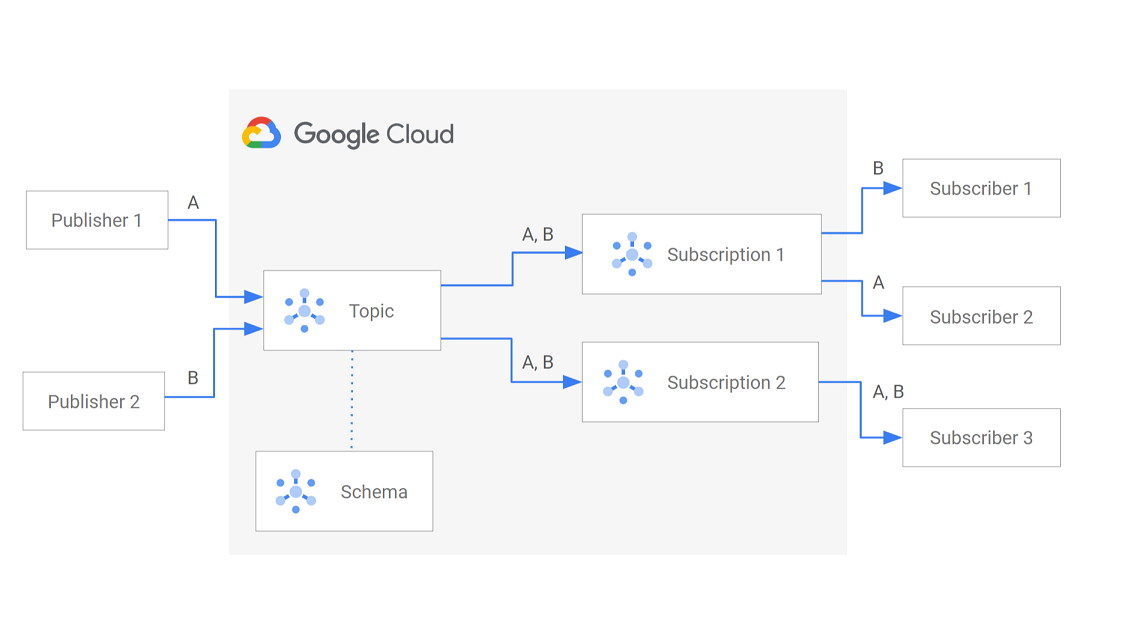
Pub/Sub サービスの概要 | Pub/Sub ドキュメント | Google Cloud より
Pub/Sub は Publisher も Subscriber も両方設定が必要だし、HTTP で受け取れるとは決まってない。(Google Cloud Pub/Sub には HTTP push の機能もある。)
Cloud Tasksについて
Cloud Tasksの基本
- task は HTTP で渡すと決まっている(Pub/Sub の場合は決まっていない)
- task 側で handler (どの URL で処理すべきなのか)を決める
Rails + CloudTasksのイメージ
HTTP の向き先を自分自身に向けるだけで Web アプリは自身で通常のリクエストと同様にバックグラウンドジョブを処理できる。
自身で処理するので一つのアプリで処理する全体のコストはは変わらないが、
- retry の機能が自動的に加わる
- 非同期なので UI への response に掛かる時間は短縮できる
ことを期待できる。
※ ただし Heroku の 30 秒制限のように Web アプリ専用のホスティングはたいてい実行時間の制限があるので、バックグラウンドジョブを HTTP で受け付けるのに向いていないプラットフォームはある。Google Cloud は App Engine, Cloud Run で 10分間は実行できる。Functions の第2世代では 60分間実行できるので、こうした考え方を適用することができる。
ActiveJob adapterはCloudtaskerが楽
検討したのは
- esminc/activejob-google_cloud_tasks-http: Active Job adapter for Google Cloud Tasks HTTP targets
- keypup-io/cloudtasker: Background jobs for Ruby using Google Cloud Tasks
シンプルなのは ActiveJob::GoogleCloudTasks::HTTP の方。ただし development 環境の支援はない。以下の設定をすれば動かすことはできるが。
- Cloud Tasks にジョブを投げるにはサービスアカウントのキーを持ち出して local から Google Cloud Tasks に接続する
- Cloud Tasks から development のサーバに tasks を投げるには投げる task の handler を ngrok などで development に向け直す
これはこれで面倒かつ 本物の Cloud を利用するので遅延と利用料金が発生するので、produtcion 以外では別の adapter (例えば async とか)に切り替えてしまう方法もなくはない。ただし、別の adapter に切り替えたまま開発を進めていくのはどうなんだろうという気にはなる。production 以外ではまったく動作していないことになるので、安心感がない。
対して Cloudtasker は development 環境では独自の Redis を利用した worker process + fake Cloud Tasks サーバで動作する。そして HTTP で task を「受ける」部分は「常に動作している」ことになる。
正直言うと Cloudtasker には単に Rails + Cloud Tasks で利用するには不要な機能がたくさんあるが、「一部でも常に動作させることができている」という安心感がある。
本当は ActiveJob::GoogleCloudTasks::HTTP を
aertje/cloud-tasks-emulator: Google cloud tasks emulator
に向けて動かすことができればそれで十分だなと思っていたのだが、いかんせんこのエミュレータにリクエストを向けるクチが標準では存在せず、どうにか設定を変更できても SSL/TLS の version の食い違いを越えることができないので断念した。
使い方
実際のコード例
wtnabe/example-rails-cloudtasker
config/cloudtasker.rb
host_file = Rails.root.join('config', 'host')
host = (File.readable?(host_file) && File.read(host_file) || 'http://localhost:3000').chomp
Cloudtasker.configure do |c|
c.processor_host = host # どうにかして自分自身のURLを決める
c.secret = <Railsのsecretを使わない場合はここに明示>
c.gcp_location_id = 'asia-northeast1'
c.gcp_project_id = ENV['PROJECT_ID']
end
app/jobs/heavy_job.rb
class HeavyJob < ApplicationJob
queue_as <queue_name> # ここで Cloud Tasks の queue 名と一致させる
def perform(*params)
...
end
end
processor_hostはどうにかして自分自身のURLをセットする
processor_host は実際に task を処理する URL のこと。development 環境と production 環境は固定でもまかなえそうだが、例えば production と staging で URL が変わります、とか特に独自のドメインを割り当てるつもりのない社内用のアプリみたいな場合はどうにかして URL 情報を取得しておいてそれをセットする必要がある。上のコード例は実際には Cloud Build で deploy の際に該当するプロジェクトの該当する Cloud Run サービスの URL を取得してそれをファイルに保存しておく処理が入っていて、Rails アプリの初期化時にその設定を拾ってセットするようになっている。何も情報がなければ development 環境としての固定値になる。
PROJECT_ID も同様に Cloud Build からサービスを deploy する際に環境変数としてセットしてあって、それを読み取っている。
※ ちなみに secret は task を JWT でエンコードする際に利用される。
残りの課題
Cloud Tasks は複数回 task が配送される可能性がある。
Cloud Tasks について理解する | Cloud Tasks のドキュメント | Google Cloud
Cloud Tasks は「少なくとも 1 回」処理を行うように設計されています。つまり、タスクが正常に追加された場合、キューはそれを少なくとも 1 回配信します。まれに複数のタスクが実行されることもあるので、反復的な実行で有害な副作用が生じないようにする必要があります。ハンドラはべき等である必要があります。
ということは、ActiveJob としては処理済みのジョブに対しても同じ task が配送されてしまう可能性がある。
ストレージへの書き込みだけなら結果整合性が取れていれば大丈夫と言えなくもないが、メール送信のように何回も実行されてはそもそも困る副作用を含むジョブを処理したい場合は、処理済みのジョブかどうかを判定する必要がある。
幸い Cloudtasker adapter は handler に job_id も task_id も渡ってくるので、真面目にやると
- 処理前に
- 保存済みの id と一致したら 200 OK
- 処理中の id と一致したら? 202 ? 409 ?
- 処理に取り掛かる id を処理中として保存
- 処理中
- 失敗する前に処理中の id を削除
- 処理後に
- 処理中の id を削除
- 処理済みの id を保存
といった仕組みが必要になるのかな。処理中の id を削除して終了しないと失敗して retry する際にそもそも retry することができなくなってしまうが、そもそも処理が長時間になるからバックグラウンドの処理に回したいので、もし多重配送が起きたら「まさに処理中」という事態は想定しておかなければいけない。もしかしてmaxConcurrentDispatches を 1 にすればもっとシンプルになるかも。少なくとも「処理中」の状態は持たなくて済むかも。
この辺の作り込みは Adapter が直接ストレージで管理している場合は気にする必要がないんじゃないかと思うが、Cloud Tasks のストレージはアプリケーションと統合されておらず、task の配送にしか責任を負わないので、ジョブの制御はアプリ側の責務となる。
まぁメールがダブって配信されてしまうことは現実には起きているだろうから、ここまでやらなくてもよいのかもしれない。何らかの情報を DB に保存する処理の場合はそこで重複が排除されるだけで済む可能性もある。どのように要件を決めるか次第ではある。